The Quality-Detectability Tradeoff: Why Worse Models Evade AI Detectors
The Core Paradox
AI content detectors are trained primarily on outputs from frontier models: GPT-5, Claude, Gemini. These models produce text that is, by most measurable standards, excellent: low perplexity, consistent sentence rhythm, aligned tone of voice. The detectors learn to recognize exactly these properties.
This creates a structural paradox: the better your model, the more detectable your output.
Optimizing for generation quality moves you toward the center of the detector's training distribution, not away from it. The implication, counterintuitive as it sounds, is that degraded text quality is a strategic asset and that the path to lower detection scores runs through deliberately worse generation.
What "Worse" Actually Means to a Detector
Detectors primarily exploit two statistical signals:
Perplexity measures how "surprising" each token choice is relative to a language model's learned probability distribution. Frontier models tend to pick near-optimal tokens consistently the text hugs the probability peak. Human writing, being imperfect, deviates from this peak far more often. A model that makes worse token choices — higher perplexity — looks more human by this metric.
Burstiness captures variance in sentence length and rhythm. Humans write in uneven bursts: a long unwieldy sentence followed by a short one. Frontier models at standard temperature produce unnaturally consistent cadence. A model with less coherent output structure, paradoxically, scores better here.
Neither of these signals has much to do with factual accuracy, argument quality, or readability. Detectability and quality are largely orthogonal dimensions. This is the key insight the playbook rests on.
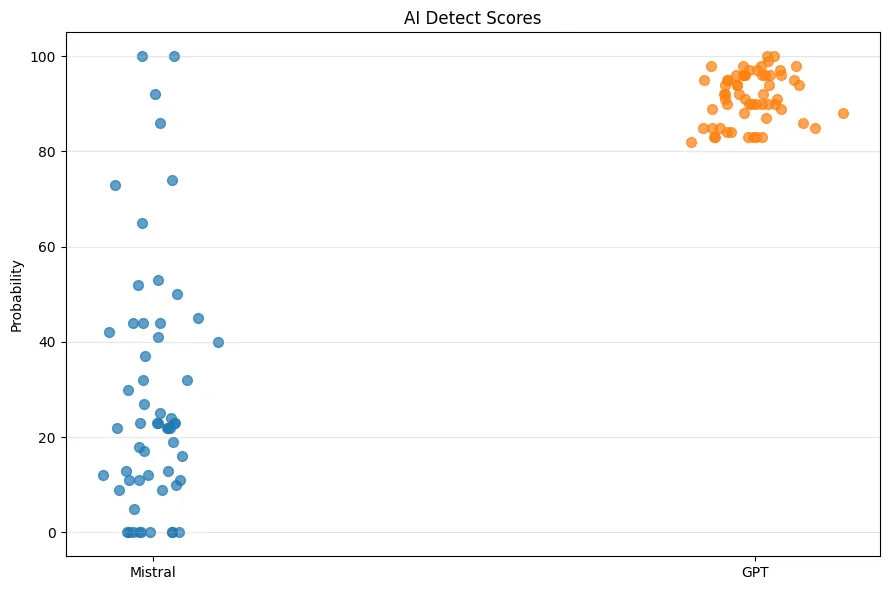
The GPT-2 Fine-Tune Finding
In our experiments, fine-tuning Mistral 7B on a corpus of GPT-2-generated summaries from 2021 reduced QuillBot detection scores from ~28% to ~14% — a 50% relative reduction — without any post-processing.
GPT-2 text is objectively poor by modern standards: repetitive, occasionally incoherent, syntactically rough. But that roughness is exactly what made the fine-tuned model's output harder to detect. The training data shifted the model's output distribution toward higher perplexity and less rhythmic consistency. The degradation was the mechanism.
This suggests a general principle: fine-tuning on historically lower-quality generated text may be more effective for detection evasion than fine-tuning on human-written text, because human writing datasets are often curated and cleaned in ways that accidentally remove the very imperfections that make text look human to a detector.
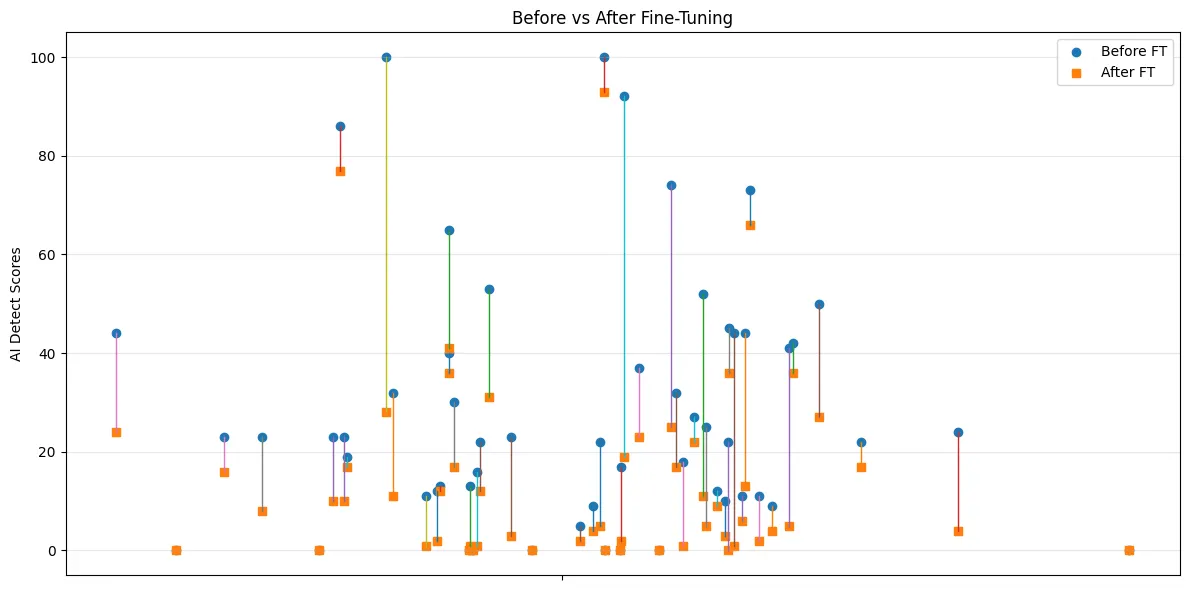
The Tradeoff Curve and Its Limits
The obvious question is: how far can this go? There is presumably a curve where, as output quality degrades further, detection scores continue to fall — until the text becomes incoherent enough to be useless. This boundary has not been systematically mapped.
From our operational experience, the degradation has two distinct failure modes:
- Factual drift — lower-quality models hallucinate more. Fine-tuning on rough data compounds this. In our multilingual pipeline, hallucination rates reached ~27% before we introduced mitigation. This is the most dangerous failure mode because it's not visible in detection scores at all.
- Readability collapse — past a certain perplexity threshold, text becomes syntactically broken in ways that no amount of post-processing recovers cleanly.
The practical implication is that you cannot simply use a worse model end-to-end. The strategy only works if you treat the two dimensions independently: use degraded generation to achieve low detectability, then engineer quality back in through separate mechanisms — vector similarity gating for factual accuracy, rule-based restructuring for readability — that do not restore the statistical patterns detectors look for.